We have
n jobs, where every job is scheduled to be done from startTime[i] to endTime[i], obtaining a profit of profit[i].
You're given the
startTime , endTime and profit arrays, you need to output the maximum profit you can take such that there are no 2 jobs in the subset with overlapping time range.
If you choose a job that ends at time
X you will be able to start another job that starts at time X.
Example 1:
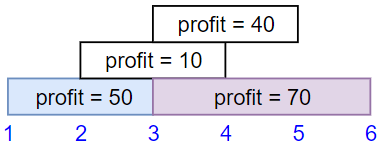
Input: startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70] Output: 120 Explanation: The subset chosen is the first and fourth job. Time range [1-3]+[3-6] , we get profit of 120 = 50 + 70.
Example 2:
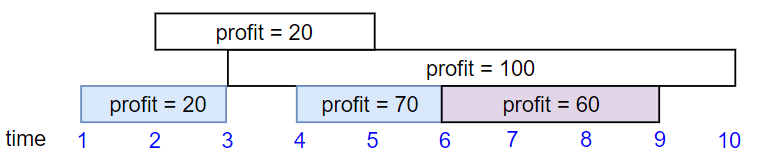
Input: startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60] Output: 150 Explanation: The subset chosen is the first, fourth and fifth job. Profit obtained 150 = 20 + 70 + 60.
Example 3:

Input: startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4] Output: 6
Constraints:
1 <= startTime.length == endTime.length == profit.length <= 5 * 10^41 <= startTime[i] < endTime[i] <= 10^91 <= profit[i] <= 10^4
问题1. startTime, endTime 是sorted么?如果不是的话,很可能我们需要先建一个data structure再自行sort.
关键点:对于每一个开始时间,我们可以用map<int, int> dp来存放,map和unordered_map的差别是,map类似于BST,里面的数字是按照key升序排列,搜索是binary search O(logn),插入一个节点rebalance也是O(logn),记得要初始化map[0] = 0,这是用来方便push in第一个初始工作的。
class Solution { public: int jobScheduling(vector<int>& startTime, vector<int>& endTime, vector<int>& profit) { int size = profit.size(); vector<vector<int>> jobs; for (int i = 0; i<size; i++) { jobs.push_back({endTime[i], startTime[i], profit[i]}); } sort(jobs.begin(), jobs.end()); map<int, int> dp; dp.insert({0, 0}); for (auto &job : jobs) { auto it = dp.upper_bound(job[1]); int cur = job[2] + prev(it)->second; if (cur > dp.rbegin()->second) { dp[job[0]] = cur; } } return dp.rbegin()->second; } };

No comments:
Post a Comment